El test de correlación cruzada se efectua para cada par de puntos según la siguiente expresión:
n: número de píxeles de la ventana
m: media aritmética de la intensidad en escala de gris de la ventana
Finalmente descarto aquellos puntos posiblemente ambiguos usando el factor lambda, de forma que sólo considero válidos aquellos puntos para los que sea cierta la siguiente condición:
Por cada pareja de puntos válida creo un vector de traslación con la presunta transformación adecuada que he de aplicar a la imagen. Finalmente hago la media aritmética de todas las transformaciones y obtengo la transformación final.
2.A. Optimizaciones
- Para evitar vectores de baja calidad he decidido aplicar un filtro al factor de correlación cruzada entre las parejas. Sólo tomaré como válidos aquellos vectores cuya CC esté por encima del 90%. Esto mejora visiblemente el resultado final ya que vectores de baja calidad, falsos positivos en la mayoría de los casos, no distorsionan la media.
- Por cada par de imágenes tomo un máximo de 250 vectores. Con esto se incrementa la velocidad sensiblemente en las imaǵenes con muchos vectores válidos (esto es: que pasan el factor lambda y tienen una CC superior al 90%). No obstante en la práctica la mayoría de las imágenes -usando un lambda por defecto de 0.95- no pasan de la centena de vectores válidos. Las que si lo hacen mejorarán su velocidad y sobretodo, su consumo de memoria; todo ello sin afectar al resultado en ninguna de las pruebas realizadas (250 vectores de alta calidad son más que suficientes para obtener la traslación correcta).
- La IA deja de buscar parejas en cuanto detecta que un punto es ambiguo. Lo consigue calculando cuanto es el máximo de CC que el segundo mejor punto puede tener frente al primero en función del lambda actual. Considerando que el primero tuviera el máximo (100%) podemos calcular que el segundo nunca debe tener más de (100*λ)%; si es así podemos descartar la búsqueda aumentando considerablemente la velocidad en imágenes con muchos puntos parecidos.
- Se fusiona toda la secuencia de imágenes sin importar el orden, siempre y cuando cada imagen sea contigua a alguna de las anteriores (que no necesariamente tiene que ser la inmediatamente anterior). En imágenes grandes y secuencias largas el tiempo de ejecución puede ser batante notable...
3. Ejecución y Funcionamiento
Esta es la pantalla de configuración con los parámetros para FPanorama: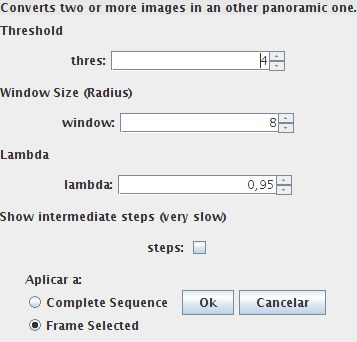
- Threshold: Argumento threshold usado para calcular los puntos por Nitzberg.
- Windows Size: Radio en píxeles de la ventana usada para la CC. A ese radio se le sumará 1 correspondiente al punto actual, de forma que un radio de 2 indica una ventana 3*3 píxeles, un radio de 3 una de 4*4, etc.
- Lambda: Factor Lambda para descartar puntos ambiguos. Debe ser un valor positivo entre 0 y 1
- Show intermediate steps: Si esta casilla está activada, aparte de crear la imagen resultado y añadirla a la secuencia, se creará también una imagen que muestre la evolución del algoritmo. Esta imagen se llamará "Poster" y mostrará cada imagen a la izquierda, y sus puntos característicos a la derecha. Cada imagen N del poster es el resultado de aplicar el algoritmo a las imágenes N-1 y N-2. Esta opción incrementa levemente el tiempo de ejecución (¡y mucho el consumo de memoria!).
4. Desarrollo y Pruebas
Cuando hacemos fotos con una cámara convencional, a pesar de intentar hacer traslaciones perfectas de nuestra posición (sin rotar ni cambiar la profundidad de la cámara) lo normal es que la cámara gire y rote levemente. Debido a esto la perspectiva cambia completamente y las imágenes resultantes no pueden ser unidas de forma suave y perfecta (este efecto se mitiga cuando se fotografían paisajes y escenas en las que todos los objetos están muy lejanos, pues simulan ser un plano frontal 2D).Así que lo primero para probar si el algoritmo funciona bien es huir de las imágenes reales y hacer pruebas con imágenes enteras, cortadas a propósito para la ocasión, y dejar que la IA trate de unirlas como si de un puzzble se tratase.
Nota: Dentro de la carpeta "imagenes/perfectas" de la entrega están todas las imágenes usadas en esta sección.
Ejemplo 1: Mi hamster
Usando los parámetros por defecto y la siguiente lista de imágenes:

Lista de imágenes usadas
La función devuelve el siguiente resultado:

Resultado final con parámetros por defecto
Ejemplo 2: Una mantis en la universidad
Usando los parámetros por defecto (y activando "steps"), y la siguiente lista de imágenes:





Lista de imaǵenes usadas
La función devuelve el siguiente resultado:

Resultado devuelto con parámetros por defecto
Y el poster con la evolución:

Cada imagen N del poster es el resultado de fusionar las imaǵenes N-1 y N-2.
Ejemplo 3: Lenna (L)
Lenna es una imagen muy especial, porque tiene muy poco contraste y todos los colores son planos y de tonos pastel. Por ello es necesario usar un tamaño de ventana mayor para obtener el resultado correcto. Usando la siguiente lista de imágenes y los parámetros por defecto:




Lista de imágenes usadas
La función devuelve el siguiente resultado:

Resultado con ventana de radio 8
Este resultado, aunque es aproximado es incorrecto. Dadas las características de la imagen, es necesario ampliar el tamaño de ventana. Sin cambiar nada más que el radio de la ventana de 8 a 16... el resultado devuelto ya es perfecto:

Resultado con ventana de radio 16
Ejemplo 4: Mi Ordenador
En esta imagen sucede lo mismo que con Lenna (esta vez, aunque hay colores brillantes, todos brillan en la misma intensidad de gris):




Lista de imágenes usadas
La función devuelve el siguiente resultado:

Resultado con ventana de radio 8
Este resultado, aunque bastante bueno, es incorrecto (se aprecian saltos). Sin cambiar nada más que el radio de la ventana de 8 a 16... el resultado devuelto ya es perfecto:

Resultado con ventana de radio 16
Ejemplo 5: Las montañas
Una vez comprobado que la IA funciona perfectamente con imágenes perfectas, es hora de ponerla a prueba con las imperfectas imágenes reales:

Lista de imágenes usadas

Resultado con valores por defecto

Poster con el desarrollo
Ejemplo 6: Puente



Lista de imágenes usadas

Resultado con valores por defecto
Ejemplo 7: San Francisco




Lista de imágenes usadas

Resultado con valores por defecto
Ejemplo 8: Ópera de Sídney


Lista de imágenes usadas

Resultado con valores por defecto

Poster con el desarrollo
Ejemplo 9: Mi balcón
Por último he tratado de unir 4 fotos hechas desde mi balcón (Ventana de radio 16). Estas fotos incluyen mucha rotación y suponen la prueba final para el algoritmo. Como nota adicional cabe destacar que la unión de estas imágenes ha tardado unos 7 minutos (en Core2Duo 2GHz, 1Giga de RAM) en llevarse a cabo.



Lista de imágenes usadas

Resultado con valores por defecto
A pesar de la lentitud... el resultado es más que convincente :)
Conclusiones
La efectividad del algoritmo pasa por elegir los parámetros adecuados. En imágenes con muchos pequeños detalles un tamaño de ventana excesivo puede producir errores importantes, en imágenes con pocos puntos un tamaño de ventana insuficiente también producirá errores muy visibles. El factor lambda por defecto (0.95) y el Threshold para Nitzberg han funcionado bastante bien en todas las pruebas que he hecho, sólo ha sido necesario ajustar el tamaño de ventana.En la práctica es el usuario el que debe experimentar con los parámetros para obtener el mejor resultado, he proporcionado unos parámetros por defecto que funcionan bien para la mayoría de las imágenes, pero esto no es suficiente para garantizar el mejor resultado.
La velocidad del algoritmo es su punto más débil, si bien creo que podría mejorarse sustancialmente si javavis proporcionase métodos mejores para trabajar con los datos de las imágenes. Leer y escribir píxel a píxel es muy costoso, con métodos para obtener píxeles de una banda en fragmentos cuadrados de una imagen devueltos en forma de array, y con métodos para escribir esos fragmentos en posiciones específicas la velocidad se incrementaría de forma muy muy notable.
Dado el coste computacional (tanto espacial como temporal) del algoritmo, trabajar con secuencias largas de imágenes grandes se hace imposible.
Implementación
El código es bastante claro y no necesita demasiados comentarios. Cada función realiza una parte del algoritmo según indica su nombre y su descripción (mirar comentarios en el código). La función processImg ha sido rescrita para no hacer nada (sólo se trabaja con secuencias).La función processSeq ha sido rescrita para adaptarla al funcionamiento del programa. El método principal es Process(JIPImage), que recibe una imagen de la secuencia y la fusiona con las anteriores.
Process(JIPImage) debería ser la función de partida para leer el código, es una estructura clara del algoritmo seguido.